![]()
Data Science Foundations
Lab 2: Data Hunt II¶
Instructor: Wesley Beckner
Contact: wesleybeckner@gmail.com
That's right you heard correctly. It's the data hunt part TWO.
Preparing Environment and Importing Data¶
Import Packages¶
!pip install -U plotly
Requirement already satisfied: plotly in /usr/local/lib/python3.7/dist-packages (4.4.1)
Collecting plotly
Downloading plotly-5.1.0-py2.py3-none-any.whl (20.6 MB)
[K |████████████████████████████████| 20.6 MB 1.3 MB/s
[?25hRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from plotly) (1.15.0)
Collecting tenacity>=6.2.0
Downloading tenacity-8.0.1-py3-none-any.whl (24 kB)
Installing collected packages: tenacity, plotly
Attempting uninstall: plotly
Found existing installation: plotly 4.4.1
Uninstalling plotly-4.4.1:
Successfully uninstalled plotly-4.4.1
Successfully installed plotly-5.1.0 tenacity-8.0.1
# our standard libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
from ipywidgets import interact
# our stats libraries
import random
import scipy.stats as stats
import statsmodels.api as sm
from statsmodels.formula.api import ols
import scipy
# our scikit-Learn library for the regression models
import sklearn
from sklearn import linear_model
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
Import and Clean Data¶
df = pd.read_csv("https://raw.githubusercontent.com/wesleybeckner/"\
"technology_fundamentals/main/assets/truffle_rates.csv")
df = df.loc[df['rate'] > 0]
df.head()
| base_cake | truffle_type | primary_flavor | secondary_flavor | color_group | rate | |
|---|---|---|---|---|---|---|
| 0 | Chiffon | Candy Outer | Cherry Cream Spice | Ginger Beer | Tiffany | 0.167097 |
| 1 | Chiffon | Candy Outer | Cherry Cream Spice | Ginger Beer | Tiffany | 0.153827 |
| 2 | Chiffon | Candy Outer | Cherry Cream Spice | Ginger Beer | Tiffany | 0.100299 |
| 3 | Chiffon | Candy Outer | Cherry Cream Spice | Ginger Beer | Tiffany | 0.333008 |
| 4 | Chiffon | Candy Outer | Cherry Cream Spice | Ginger Beer | Tiffany | 0.078108 |
df.shape
(9210, 6)
Exploratory Data Analysis¶
🍫 L2 Q1 Finding Influential Features¶
Which of the five features (base_cake, truffle_type, primary_flavor, secondary_flavor, color_group) of the truffles is most influential on production rate?
Back your answer with both a visualization of the distributions (boxplot, kernel denisty estimate, histogram, violin plot) and a statistical test (moods median, ANOVA, t-test)
- Be sure:
- everything is labeled (can you improve your labels with additional descriptive statistical information e.g. indicate mean, std, etc.)
- you meet the assumptions of your statistical test
🍫 L2 Q1.1 Visualization¶
Use any number of visualizations. Here is an example to get you started:
# Example: a KDE of the truffle_type and base_cake columns
fig, ax = plt.subplots(2, 1, figsize=(12,12))
sns.kdeplot(x=df['rate'], hue=df['truffle_type'], fill=True, ax=ax[0])
sns.kdeplot(x=df['rate'], hue=df['base_cake'], fill=True, ax=ax[1])
<matplotlib.axes._subplots.AxesSubplot at 0x7f549eea03d0>

/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning:
Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning:
Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning:
Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning:
Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning:
Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
/usr/local/lib/python3.7/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning:
Glyph 9 missing from current font.
/usr/local/lib/python3.7/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning:
Glyph 9 missing from current font.

🍫 L2 Q1.2 Statistical Analysis¶
What statistical tests can you perform to evaluate your hypothesis from the visualizations (maybe you think one particular feature is significant). Here's an ANOVA on the truffle_type column to get you started:
model = ols('rate ~ C({})'.format('truffle_type'), data=df).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
display(anova_table)
| sum_sq | df | F | PR(>F) | |
|---|---|---|---|---|
| C(truffle_type) | 36.383370 | 2.0 | 302.005 | 9.199611e-128 |
| Residual | 554.596254 | 9207.0 | NaN | NaN |
Is this P value significant? What is the null hypothesis? How do we check the assumptions of ANOVA?
base_cake
| sum_sq | df | F | PR(>F) | |
|---|---|---|---|---|
| C(base_cake) | 331.373550 | 5.0 | 2349.684756 | 0.0 |
| Residual | 259.606073 | 9204.0 | NaN | NaN |
Shapiro: 0.9281061887741089 0.0
Bartlett: 619.3727153356931 1.3175663824168166e-131
truffle_type
/usr/local/lib/python3.7/dist-packages/scipy/stats/morestats.py:1676: UserWarning:
p-value may not be accurate for N > 5000.
| sum_sq | df | F | PR(>F) | |
|---|---|---|---|---|
| C(truffle_type) | 36.383370 | 2.0 | 302.005 | 9.199611e-128 |
| Residual | 554.596254 | 9207.0 | NaN | NaN |
Shapiro: 0.9645588994026184 1.3704698981096711e-42
/usr/local/lib/python3.7/dist-packages/scipy/stats/morestats.py:1676: UserWarning:
p-value may not be accurate for N > 5000.
Bartlett: 533.0206680979852 1.8031528902362296e-116
primary_flavor
| sum_sq | df | F | PR(>F) | |
|---|---|---|---|---|
| C(primary_flavor) | 159.105452 | 47.0 | 71.815842 | 0.0 |
| Residual | 431.874171 | 9162.0 | NaN | NaN |
/usr/local/lib/python3.7/dist-packages/scipy/stats/morestats.py:1676: UserWarning:
p-value may not be accurate for N > 5000.
Shapiro: 0.9738250970840454 6.485387538059916e-38
Bartlett: 1609.0029005171464 1.848613457353585e-306
secondary_flavor
| sum_sq | df | F | PR(>F) | |
|---|---|---|---|---|
| C(secondary_flavor) | 115.773877 | 28.0 | 79.884192 | 0.0 |
| Residual | 475.205747 | 9181.0 | NaN | NaN |
Shapiro: 0.9717048406600952 4.3392384038527993e-39
Bartlett: 1224.4882890761903 3.5546073028894766e-240
color_group
/usr/local/lib/python3.7/dist-packages/scipy/stats/morestats.py:1676: UserWarning:
p-value may not be accurate for N > 5000.
| sum_sq | df | F | PR(>F) | |
|---|---|---|---|---|
| C(color_group) | 33.878491 | 11.0 | 50.849974 | 1.873235e-109 |
| Residual | 557.101132 | 9198.0 | NaN | NaN |
Shapiro: 0.9598756432533264 1.401298464324817e-44
Bartlett: 298.6432027161358 1.6917844519244488e-57
/usr/local/lib/python3.7/dist-packages/scipy/stats/morestats.py:1676: UserWarning:
p-value may not be accurate for N > 5000.
🍫 L2 Q2 Finding Best and Worst Groups¶
🍫 L2 Q2.1 Compare Every Group to the Whole¶
Of the primary flavors (feature), what 5 flavors (groups) would you recommend Truffletopia discontinue?
Iterate through every level (i.e. pound, cheese, sponge cakes) of every category (i.e. base cake, primary flavor, secondary flavor) and use moods median testing to compare the group distribution to the grand median rate.
(98, 10)
After you've computed a moods median test on every group, filter any data above a significance level of 0.05
(76, 10)
Return the groups with the lowest median performance (your table need not look exactly like the one I've created)
| descriptor | group | pearsons_chi_square | p_value | grand_median | group_mean | group_median | size | welch p | table | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | primary_flavor | Coconut | 56.8675 | 4.66198e-14 | 0.310345 | 0.139998 | 0.0856284 | 100 | 2.64572e-29 | [[12, 4593], [88, 4517]] |
| 1 | secondary_flavor | Wild Cherry Cream | 56.8675 | 4.66198e-14 | 0.310345 | 0.139998 | 0.0856284 | 100 | 2.64572e-29 | [[12, 4593], [88, 4517]] |
| 2 | primary_flavor | Pink Lemonade | 61.5563 | 4.30253e-15 | 0.310345 | 0.129178 | 0.0928782 | 85 | 2.05798e-28 | [[6, 4599], [79, 4526]] |
| 3 | primary_flavor | Chocolate | 51.3203 | 7.84617e-13 | 0.310345 | 0.145727 | 0.0957584 | 91 | 1.11719e-28 | [[11, 4594], [80, 4525]] |
| 4 | primary_flavor | Wild Cherry Cream | 43.5452 | 4.14269e-11 | 0.310345 | 0.148964 | 0.10588 | 70 | 2.59384e-20 | [[7, 4598], [63, 4542]] |
| 5 | secondary_flavor | Mixed Berry | 164.099 | 1.43951e-37 | 0.310345 | 0.153713 | 0.115202 | 261 | 6.73636e-75 | [[28, 4577], [233, 4372]] |
| 6 | secondary_flavor | Peppermint | 66.0235 | 4.45582e-16 | 0.310345 | 0.129107 | 0.12201 | 86 | 7.6449e-37 | [[5, 4600], [81, 4524]] |
| 7 | base_cake | Butter | 696.649 | 1.60093e-153 | 0.310345 | 0.15951 | 0.136231 | 905 | 0 | [[75, 4530], [830, 3775]] |
| 8 | secondary_flavor | Rum | 69.5192 | 7.56747e-17 | 0.310345 | 0.157568 | 0.139834 | 93 | 4.42643e-42 | [[6, 4599], [87, 4518]] |
| 9 | secondary_flavor | Cucumber | 175.061 | 5.80604e-40 | 0.310345 | 0.170015 | 0.14097 | 288 | 4.33234e-79 | [[33, 4572], [255, 4350]] |
| 10 | primary_flavor | Gingersnap | 131.114 | 2.33844e-30 | 0.310345 | 0.159268 | 0.143347 | 192 | 1.01371e-69 | [[17, 4588], [175, 4430]] |
| 11 | primary_flavor | Cherry Cream Spice | 66.3302 | 3.81371e-16 | 0.310345 | 0.175751 | 0.146272 | 100 | 1.03408e-36 | [[9, 4596], [91, 4514]] |
| 12 | primary_flavor | Orange Brandy | 97.0624 | 6.71776e-23 | 0.310345 | 0.185908 | 0.157804 | 186 | 1.86398e-49 | [[26, 4579], [160, 4445]] |
| 13 | primary_flavor | Irish Cream | 87.5008 | 8.42448e-21 | 0.310345 | 0.184505 | 0.176935 | 151 | 6.30631e-52 | [[18, 4587], [133, 4472]] |
| 14 | base_cake | Chiffon | 908.383 | 1.47733e-199 | 0.310345 | 0.208286 | 0.177773 | 1821 | 0 | [[334, 4271], [1487, 3118]] |
| 15 | primary_flavor | Ginger Lime | 40.1257 | 2.38138e-10 | 0.310345 | 0.225157 | 0.181094 | 100 | 2.63308e-18 | [[18, 4587], [82, 4523]] |
| 16 | primary_flavor | Doughnut | 98.4088 | 3.40338e-23 | 0.310345 | 0.234113 | 0.189888 | 300 | 1.03666e-40 | [[65, 4540], [235, 4370]] |
| 17 | primary_flavor | Butter Milk | 28.3983 | 9.87498e-08 | 0.310345 | 0.237502 | 0.190708 | 100 | 1.96333e-20 | [[23, 4582], [77, 4528]] |
| 18 | primary_flavor | Pecan | 40.8441 | 1.64868e-10 | 0.310345 | 0.197561 | 0.192372 | 89 | 2.86564e-25 | [[14, 4591], [75, 4530]] |
| 19 | secondary_flavor | Dill Pickle | 69.8101 | 6.52964e-17 | 0.310345 | 0.228289 | 0.19916 | 241 | 6.39241e-33 | [[56, 4549], [185, 4420]] |
We would want to cut the following primary flavors. Check to see that you get a similar answer. rip wild cherry cream.
['Coconut', 'Pink Lemonade', 'Chocolate', 'Wild Cherry Cream', 'Gingersnap']
['Coconut', 'Pink Lemonade', 'Chocolate', 'Wild Cherry Cream', 'Gingersnap']
🍫 L2 Q2.2 Beyond Statistical Testing: Using Reasoning¶
Let's look at the total profile of the products associated with the five worst primary flavors. Given the number of different products made with any of these flavors, would you alter your answer at all?
# 1. filter df for only bottom five flavors
# 2. groupby all columns besides rate
# 3. describe the rate column.
# by doing this we can evaluate just how much sampling variety we have for the
# worst performing flavors.
bottom_five = ['Coconut', 'Pink Lemonade', 'Chocolate', 'Wild Cherry Cream', 'Gingersnap']
df.loc[df['primary_flavor'].isin(bottom_five)].groupby(list(df.columns[:-1]))['rate'].describe()
| count | mean | std | min | 25% | 50% | 75% | max | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base_cake | truffle_type | primary_flavor | secondary_flavor | color_group | ||||||||
| Butter | Jelly Filled | Pink Lemonade | Butter Rum | Rose | 85.0 | 0.129178 | 0.137326 | 0.000061 | 0.032887 | 0.092878 | 0.171350 | 0.860045 |
| Chiffon | Candy Outer | Wild Cherry Cream | Rock and Rye | Olive | 17.0 | 0.094287 | 0.059273 | 0.010464 | 0.053976 | 0.077098 | 0.120494 | 0.229933 |
| Chocolate Outer | Gingersnap | Dill Pickle | Burgundy | 59.0 | 0.133272 | 0.080414 | 0.021099 | 0.069133 | 0.137972 | 0.172066 | 0.401387 | |
| Jelly Filled | Chocolate | Tutti Frutti | Burgundy | 91.0 | 0.145727 | 0.135230 | 0.000033 | 0.044847 | 0.095758 | 0.185891 | 0.586570 | |
| Pound | Candy Outer | Coconut | Wild Cherry Cream | Taupe | 100.0 | 0.139998 | 0.147723 | 0.000705 | 0.036004 | 0.085628 | 0.187318 | 0.775210 |
| Chocolate Outer | Gingersnap | Rock and Rye | Black | 67.0 | 0.156160 | 0.110666 | 0.002846 | 0.074615 | 0.139572 | 0.241114 | 0.551898 | |
| Jelly Filled | Gingersnap | Kiwi | Taupe | 66.0 | 0.185662 | 0.132272 | 0.000014 | 0.086377 | 0.166340 | 0.247397 | 0.593016 | |
| Wild Cherry Cream | Mango | Taupe | 53.0 | 0.166502 | 0.160090 | 0.001412 | 0.056970 | 0.108918 | 0.207306 | 0.787224 |
🍫 L2 Q2.3 The Jelly Filled Conundrum¶
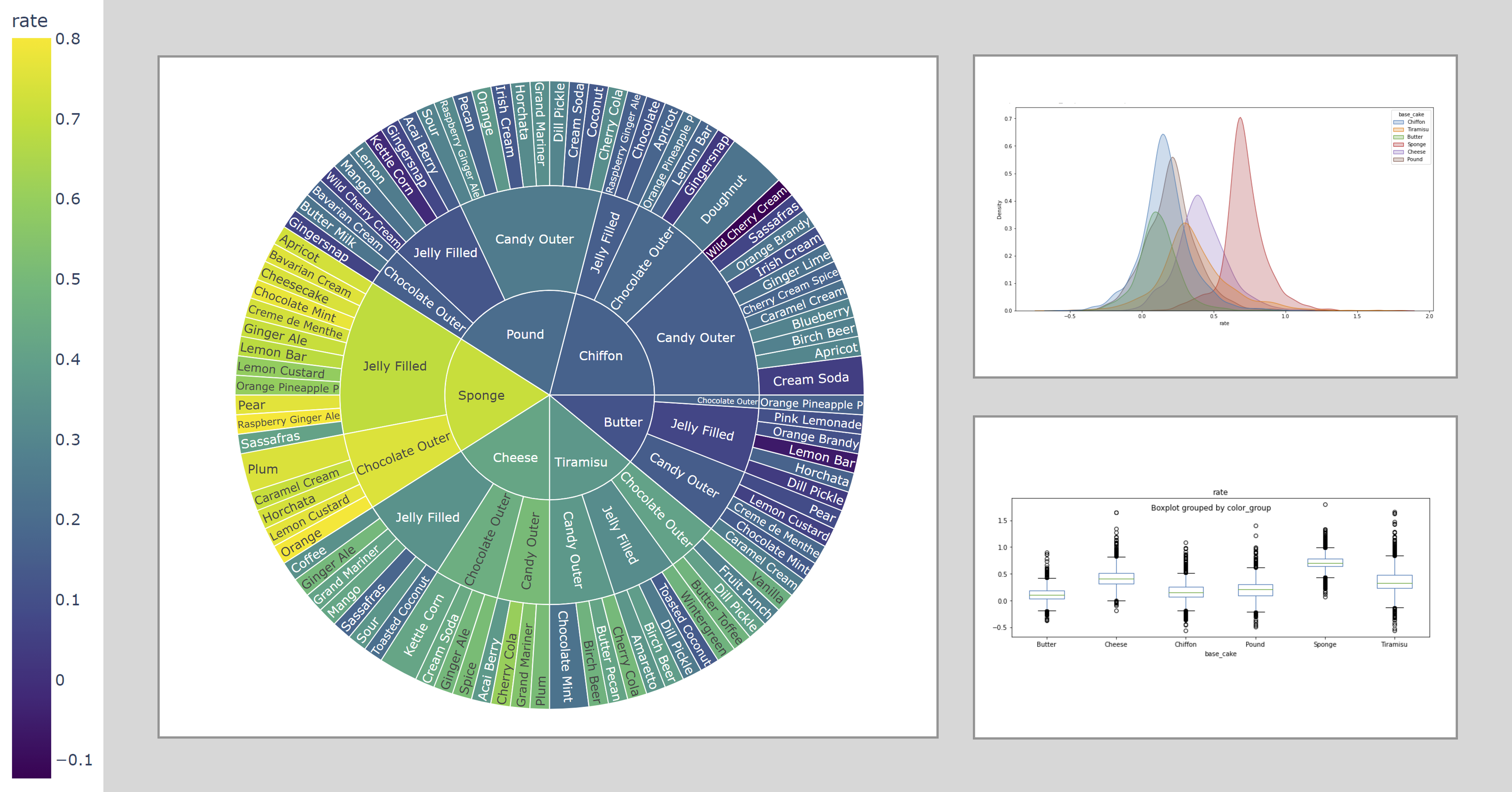
Your boss notices the Jelly filled truffles are being produced much faster than the candy outer truffles and suggests expanding into this product line. What is your response? Use the visualization tool below to help you think about this problem, then create any visualizations or analyses of your own.
def sun(path=[['base_cake', 'truffle_type', 'primary_flavor', 'secondary_flavor', 'color_group'],
['truffle_type', 'base_cake', 'primary_flavor', 'secondary_flavor', 'color_group']]):
fig = px.sunburst(df, path=path,
color='rate',
color_continuous_scale='viridis',
)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
height=650
)
fig.show()
interact(sun)
interactive(children=(Dropdown(description='path', options=(['base_cake', 'truffle_type', 'primary_flavor', 's…
<function __main__.sun>