General Applications of Neural Networks
Session 6: Recurrent Neural Networks and Time Series Analysis¶
Instructor: Wesley Beckner
Contact: wesleybeckner@gmail.com
In this session, we'll be exploring NN as they apply to sequenced data, specifically time series data.
6.0 Preparing Environment and Importing Data¶
6.0.1 Import Packages¶
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px
import random
from scipy.stats import gamma, norm, expon
from ipywidgets import interact
from statsmodels.tsa.stattools import pacf, acf
from sklearn.metrics import mean_squared_error
def melt_results(model, X, y, window_size):
y_pred = model.predict(X)
results = pd.DataFrame(y_pred, y)
results = results.reset_index()
results.index = orders.loc[0, time_cols].index[window_size:]
results = results.reset_index()
results.columns=['Date', 'real', 'predicted']
results = results.melt(id_vars='Date', var_name='Source', value_name='KG')
return results
def process_data(Xy, window=3, time_cols=12, remove_null=False):
"""
This function splits your time series data into the proper windows
Parameters
----------
Xy: array
The input data. If there are non-time series columns, assumes they are on
the left and time columns are on the right.
time_cols: int
The number of time columns, default 12
window: int
The time window size, default 3
Returns
-------
X_: array
The independent variables, includes time and non-time series columns with
the new window
y_: array
The dependent variable, selected from the time columns at the end of the
window
labels:
The time series labels, can be used in subsequent plot
"""
# separate the non-time series columns
X_cat = Xy[:,:-time_cols]
# select the columns to apply the sweeping window
X = Xy[:,-time_cols:]
X_ = []
y = []
for i in range(X.shape[1]-window):
# after attaching the current window to the non-time series
# columns, add it to a growing list
X_.append(np.concatenate((X_cat, X[:, i:i+window]), axis=1))
# add the next time delta after the window to the list of y
# values
y.append(X[:, i+window])
# X_ is 3D: [number of replicates from sweeping window,
# length of input data,
# size of new feature with categories and time]
# we want to reshape X_ so that the replicates due to the sweeping window is
# a part of the same dimension as the instances of the input data
X_ = np.array(X_).reshape(X.shape[0]*np.array(X_).shape[0],window+X_cat.shape[1])
y = np.array(y).reshape(X.shape[0]*np.array(y).shape[0],)
if remove_null:
# remove training data where the target is 0 (may be unfair advantage)
X_ = X_[np.where(~np.isnan(y.astype(float)))[0]]
y = y[np.where(~np.isnan(y.astype(float)))[0]]
# create labels that show the previous month values used to train the model
labels = []
for row in X_:
labels.append("X: {}".format(np.array2string(row[-window:].astype(float).round())))
return X_, y, labels
def train_test_process(data, train_test_val_ratios = [0.6, 0.8], window_size=3):
# get the indices at the associated ratios
idx_split1 = int(data.shape[1]*train_test_val_ratios[0])
idx_split2 = int(data.shape[1]*train_test_val_ratios[1])
# index the data to build the sets
data_train = data[:,:idx_split1]
data_val = data[:,idx_split1:idx_split2]
data_test = data[:,idx_split2:]
# build out the training sets with the sweeping window method
X_train, y_train, labels = process_data(data_train, window=window_size, time_cols=132)
X_val, y_val, labels = process_data(data_val, window=window_size, time_cols=132)
X_test, y_test, labels = process_data(data_test, window=window_size, time_cols=132)
print("train size: {}".format(X_train.shape[0]))
print("val size: {}".format(X_val.shape[0]))
print("test size: {}".format(X_test.shape[0]), end='\n\n')
return X_train, y_train, X_val, y_val, X_test, y_test
6.0.2 Load Dataset¶
orders = pd.read_csv("https://raw.githubusercontent.com/wesleybeckner/"\
"truffletopia/main/truffletopia/data/12_year_orders.csv")
cat_cols = ['base_cake', 'truffle_type', 'primary_flavor', 'secondary_flavor',
'color_group', 'customer']
time_cols = [i for i in orders.columns if i not in cat_cols]
# note that our data is 'untidy' if we wanted to tidy the data we would need to
# unpivot or 'melt' our date columns like so:
orders.melt(id_vars=cat_cols, var_name='date', value_name='kg')
# however the data as it is, is useful for our purposes of timeseries prediction
# today
| base_cake | truffle_type | primary_flavor | secondary_flavor | color_group | customer | date | kg | |
|---|---|---|---|---|---|---|---|---|
| 0 | Cheese | Candy Outer | Horchata | Vanilla | Amethyst | Perk-a-Cola | 1/2010 | 12570.335165 |
| 1 | Tiramisu | Chocolate Outer | Irish Cream | Egg Nog | Slate | Dandy's Candies | 1/2010 | 7922.970436 |
| 2 | Sponge | Chocolate Outer | Ginger Ale | Apple | Slate | Dandy's Candies | 1/2010 | 10521.306722 |
| 3 | Cheese | Chocolate Outer | Coffee | Pear | Opal | Dandy's Candies | 1/2010 | 4739.122200 |
| 4 | Chiffon | Jelly Filled | Butter Toffee | Apricot | Olive | Slugworth | 1/2010 | 2756.891961 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 13195 | Chiffon | Chocolate Outer | Acai Berry | Tangerine | Slate | Fickelgruber | 12/2020 | 25714.512372 |
| 13196 | Butter | Jelly Filled | Plum | Peppermint | Olive | Fickelgruber | 12/2020 | 15043.303525 |
| 13197 | Chiffon | Chocolate Outer | Wild Cherry Cream | Peppermint | Taupe | Perk-a-Cola | 12/2020 | 8769.613116 |
| 13198 | Cheese | Candy Outer | Mango | Mango | Rose | Dandy's Candies | 12/2020 | 5065.975534 |
| 13199 | Sponge | Chocolate Outer | Ginger Ale | Passion Fruit | Black | Fickelgruber | 12/2020 | 9466.712219 |
13200 rows × 8 columns
6.1 Why We Think in Sequences¶
There are some problems that are best framed as a sequence in either the input or the output. For example, in our image classification we are performing a mapping of many-to-one: sequence input (the pixels) to a single output (classification). Other examples include:
- One-to-many: sequence output, e.x. word (if treated as a single input) to generate a picture
- Many-to-many: sequence input and output, e.x. machine translation (like english to mandarin)
- Synchronized many-to-many: synced sequence input and output, e.x. video classification
State of the art handling of sequences has occurred in a class of networks called recurrent neural networks
6.2 Recurrent Neural Networks¶
Recurrent Neural Networks (RNNs) can be thought of as a FFNN with loops added into the architecture. This allows the network to retain information, create "memory" that can be associated with signals later in the sequence.
We didn't go into much detail about the actual training algorithm of neural networks: back propagation. But what we will say here, is that this algorithm breaks down with recurrent neural networks because of the looped connections. A trick was created to overcome this, where the looped connections are unrolled, using a copy of the "unhooked" neuron to represent where the loop was initally fed back. This algorithm is called back propagation through time.
Another problem is introduced when training recurrent neural networks, in that the gradients calculated during back propagation can become very large, exploding gradients, or very small vanishing gradients. This problem is modulated in FNNNs by the ReLU, In RNNs, a more sophisticated gating mechanism is used in an architecture we call Long Short-Term Memory Networks
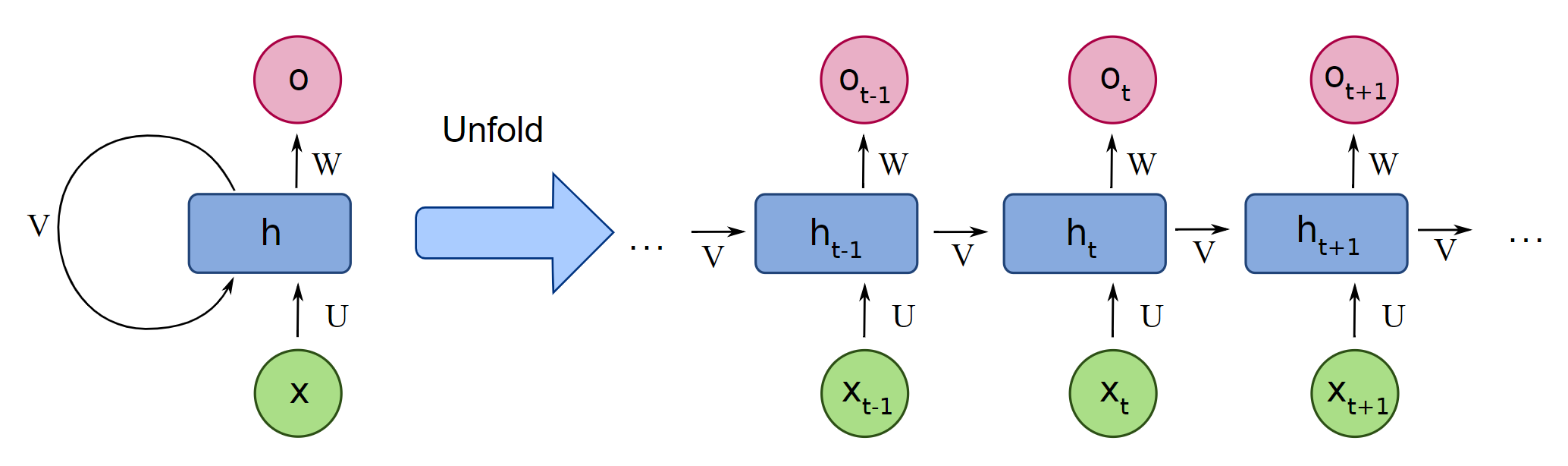
LSTM shown in both typical and unfolded format
6.2.1 Long Short-Term Memory Networks¶
Long Short-Term Memory Networks (LSTMs) are a type of RNN that are trained using back propagation through time and overcome the vanishing/exploding gradient problem. Similar to CNNs, their architecture is composed of blocks, this time with memory blocks rather than convolutional blocks. A block is smarter than the classical neuron; it contains gates that manage the block's state and output. The gates are operated by a sigmoid function, determining whether they are open or closed (triggered or not trigerred). There are three types of gates within a memory block:
- Forget gate: decides what information is discarded
- Input gate: decides what information updates the memory state
- Output gate: decides what information to send forward depending on the input and memory state
These weights that configure these gates are learned during training, and their coordination allow each memory block to learn sophisticated relationships in and among sequenced data.
Big takeaway: memory blocks contain trainable parameters that allow the block to learn relationships between sequenced data
6.3 Exploratory Data Analysis with Plotly/Pandas¶
orders.head()
| base_cake | truffle_type | primary_flavor | secondary_flavor | color_group | customer | 1/2010 | 2/2010 | 3/2010 | 4/2010 | ... | 3/2020 | 4/2020 | 5/2020 | 6/2020 | 7/2020 | 8/2020 | 9/2020 | 10/2020 | 11/2020 | 12/2020 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Cheese | Candy Outer | Horchata | Vanilla | Amethyst | Perk-a-Cola | 12570.335165 | 11569.168746 | 13616.812204 | 11884.370881 | ... | 21575.521051 | 18856.178110 | 20701.250676 | 19406.448560 | 22328.687163 | 19384.824042 | 21449.154890 | 19554.405590 | 21873.104938 | 19572.860127 |
| 1 | Tiramisu | Chocolate Outer | Irish Cream | Egg Nog | Slate | Dandy's Candies | 7922.970436 | 6464.558625 | 6616.092291 | 8244.991928 | ... | 10145.394106 | 13132.925131 | 10821.805709 | 10829.961838 | 12995.340352 | 10504.814195 | 10617.199735 | 13377.165673 | 11065.835571 | 11135.386324 |
| 2 | Sponge | Chocolate Outer | Ginger Ale | Apple | Slate | Dandy's Candies | 10521.306722 | 5543.335645 | 5294.892374 | 11010.452413 | ... | 8516.098910 | 17498.911792 | 8369.846849 | 8334.206937 | 17519.678690 | 8595.378915 | 8909.348040 | 17234.636475 | 9002.216839 | 8794.467252 |
| 3 | Cheese | Chocolate Outer | Coffee | Pear | Opal | Dandy's Candies | 4739.122200 | 2733.281035 | 4984.394797 | 2750.709519 | ... | 8093.541144 | 4301.081977 | 8235.616589 | 4151.474242 | 8213.665500 | 4008.885583 | 7912.641813 | 4275.162782 | 8031.227879 | 4628.989194 |
| 4 | Chiffon | Jelly Filled | Butter Toffee | Apricot | Olive | Slugworth | 2756.891961 | 1739.900797 | 1791.975108 | 1533.023665 | ... | 1864.015449 | 1800.566323 | 1625.130275 | 1908.316219 | 2696.631511 | 1859.017636 | 1690.042699 | 1764.410866 | 1909.608709 | 1711.780317 |
5 rows × 138 columns
data = pd.DataFrame(orders.loc[0, time_cols])
data = data.reset_index()
data.columns = ['Date', 'KG']
data
px.scatter(data, x='Date', y='KG')
fig, ax = plt.subplots(1,1,figsize=(10,10))
pd.plotting.autocorrelation_plot(data['KG'], ax=ax)
<matplotlib.axes._subplots.AxesSubplot at 0x7ff3c213eb50>
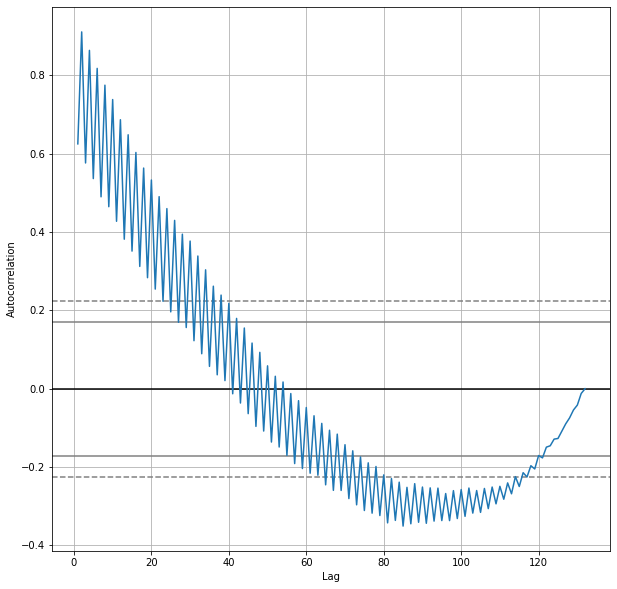
Normally with time series data, we'd want to try a host of preprocessing techniques and remove the trend (really create two separate analyses, one of the trend and one of the seasonality) but to keep things simple and to showcase the utility of machine learning, we are going to deviate from the stats-like approach and work with our data as is.
For more details on the stats-like models you can perform a cursory search on ARIMA, ARMA, SARIMA
6.4 Modeling¶
from tensorflow import keras
from tensorflow.keras import layers
6.4.1 Sweeping (Rolling) Window¶
We're going to revist this idea of a sweeping window from our feature engineering disucssion. It turns out, even though we are using a NN, there is still some preprocessing we need to do. In our case, each time delta is represented by a month. So we will choose some number of months to include in our feature set, this will in turn determine what our overall training data will look like.
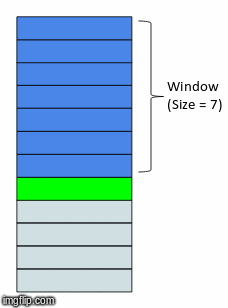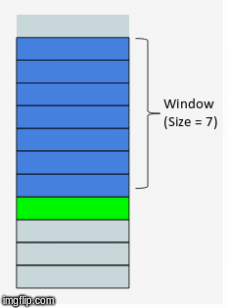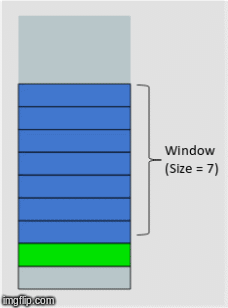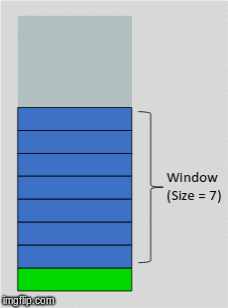
Xy = orders.loc[[0], time_cols].values
# separate the non-time series columns
X_cat = Xy[:,:-120]
# select the columns to apply the sweeping window
X = Xy[:,-120:]
with a window size of 3, our X will have 3 features, the prior 3 months leading up to the month for which we will attempt to forecast.
window_size = 3
X, y, labels = process_data(orders.loc[[0], time_cols].values, window=window_size, time_cols=132)
X[:5]
array([[12570.33516483, 11569.16874623, 13616.81220446],
[11569.16874623, 13616.81220446, 11884.37088102],
[13616.81220446, 11884.37088102, 13950.33233441],
[11884.37088102, 13950.33233441, 12781.15653568],
[13950.33233441, 12781.15653568, 14256.21002336]])
With a window size of 1, our X data will have a feature size of 1
window_size = 1
X, y, labels = process_data(orders.loc[[0], time_cols].values, window=window_size, time_cols=132)
X[:5]
array([[12570.33516483],
[11569.16874623],
[13616.81220446],
[11884.37088102],
[13950.33233441]])
and so on.
6.4.2 FFNN¶
I'm going to start with a very simple FFNN model:
model = keras.Sequential([
layers.Dense(8, input_shape=[window_size]), # one layer, 8 nodes
layers.Dense(1) # single output for the kg
])
model.compile(loss='mean_squared_error', optimizer='adam')
early_stopping = keras.callbacks.EarlyStopping(
patience=10,
min_delta=0.001,
restore_best_weights=True,
monitor='loss'
)
history = model.fit(
X, y,
batch_size=10,
epochs=1000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
history_df = pd.DataFrame(history.history)
history_df.tail()
| loss | |
|---|---|
| 19 | 4.243438e+06 |
| 20 | 4.240187e+06 |
| 21 | 4.240501e+06 |
| 22 | 4.247284e+06 |
| 23 | 4.238702e+06 |
As we can see from the y vs y_pred the FFNN is just predicting the previous month's value:
y_pred = model.predict(X)
pd.DataFrame(y_pred, y)
| 0 | |
|---|---|
| 11569.168746 | 12562.842773 |
| 13616.812204 | 11562.307617 |
| 11884.370881 | 13608.662109 |
| 13950.332334 | 11877.311523 |
| 12781.156536 | 13941.969727 |
| ... | ... |
| 19384.824042 | 22315.048828 |
| 21449.154890 | 19373.041016 |
| 19554.405590 | 21436.068359 |
| 21873.104938 | 19542.517578 |
| 19572.860127 | 21859.757812 |
131 rows × 1 columns
We can try this with a more suitable window size
window_size = 3
X, y, labels = process_data(orders.loc[[0], time_cols].values, window=window_size, time_cols=132)
model = keras.Sequential([
# layers.Dense(8, input_shape=[window_size]),
layers.Dense(1, input_shape=[window_size])
])
model.compile(loss='mean_squared_error', optimizer='adam')
history = model.fit(
X, y,
batch_size=10,
epochs=1000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
history_df = pd.DataFrame(history.history)
history_df.tail()
| loss | |
|---|---|
| 752 | 550135.6875 |
| 753 | 555000.3750 |
| 754 | 550800.3125 |
| 755 | 551368.6250 |
| 756 | 548760.4375 |
A cursory glance looks like our values are closer together
results = melt_results(model, X, y, window_size)
px.line(results, x='Date', y='KG', color='Source')
🏋️ Exercise-Discussion 1: Varify that the model is linear¶
We're having to change our way of thinking here with time series analysis. Recall that a model without an activation function can only encapsulate linear relationships. How come we can see non-linear relationships in our time series plot above? make a plot that showcases we are indeed still within a linear world.
This is an open ended question, think about how you would attempt to show linearity of the model. (In Lab 1 our model predicted on only 2 dimensions (vs 3, in this case), and it was a binary classification task, so it was easier to view the decision boundaries and verify linearity).
# Code cell for Exercise 1
🏋️ Exercise 2: Vary model architecture and window size¶
Create these three different models. Train on the whole dataset with a window size of 3. record the training loss for the last 5 epochs of each model
models = [
keras.Sequential([
layers.Dense(8, input_shape=[window_size]),
layers.Dense(1)
]),
keras.Sequential([
layers.Dense(8, activation='relu', input_shape=[window_size]),
layers.Dense(1)
]),
keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[window_size]),
layers.Dense(1)
])]
You can create the training sets with:
window_size = 3
X, y, labels = process_data(orders.loc[[0], time_cols].values, window=window_size, time_cols=132)
Use a batch size of 10 when training.
When you are finished training a model use melt_results and plotly to make a graph of your predictions vs actuals
df = melt_results(model, X, y, window_size)
px.line(df, x='Date', y='KG', color='Source')
You can use the same early_stopping and fit formula from 6.4.2
# Code cell for exercise 2
window_size = 3
batch_size = 10
models = [
keras.Sequential([
layers.Dense(8, input_shape=[window_size]),
layers.Dense(1)
]),
keras.Sequential([
layers.Dense(8, activation='relu', input_shape=[window_size]),
layers.Dense(1)
]),
keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[window_size]),
layers.Dense(1)
])]
X, y, labels = process_data(orders.loc[[0], time_cols].values, window=window_size, time_cols=132)
dfs = []
for model in models:
model.compile(loss='mean_squared_error', optimizer='adam')
history = model.fit(
X, y,
batch_size=batch_size,
epochs=int(1e4),
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
print(history.history['loss'][-10:])
df = melt_results(model, X, y, window_size)
dfs.append(df)
px.line(df, x='Date', y='KG', color='Source')
[449815.4375, 438517.75, 434076.40625, 436526.9375, 431749.71875, 432751.5, 431072.125, 433903.71875, 434614.8125, 434704.71875]
[319843872.0, 319843424.0, 319842976.0, 319842528.0, 319842080.0, 319841632.0, 319841120.0, 319840704.0, 319840224.0, 319839776.0]
[398923.6875, 398456.15625, 399380.0, 399915.5, 406269.09375, 400187.28125, 397825.96875, 412889.375, 399718.75, 402859.40625]
px.line(dfs[2], x='Date', y='KG', color='Source')
6.4.3 LSTM NN¶
Our data preparation for the LSTM NN includes time steps. The parameter input_dim tells our LSTM block how man time steps we have in the input data. This is a reframing (and a more appropriate reframing) of the same problem. The LSTM model is viewing the input feature w/ multiple time steps as a single feature at different times, rather than separate features. We could, for instance, have a second dimension that includes non-time related information, such as the customer name or truffle types (or other featurse that also vary through time, multiple feed rates or T/P, etc).
window_size = 6
batch_size = 10
X, y, labels = process_data(orders.loc[[0], time_cols].values, window=window_size, time_cols=132)
X = X.reshape(-1, 1, window_size)
y = y.reshape(-1, 1, 1)
model = keras.Sequential([
layers.LSTM(8, activation='relu', input_dim=window_size),
layers.Dense(8),
layers.Dense(1)
])
model.compile(loss='mean_squared_error', optimizer='adam')
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
history = model.fit(
X, y,
batch_size=batch_size,
epochs=int(1e4),
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
history_df = pd.DataFrame(history.history)
history_df.tail()
| loss | |
|---|---|
| 4050 | 4906831.5 |
| 4051 | 4906659.0 |
| 4052 | 4906790.5 |
| 4053 | 4906763.0 |
| 4054 | 4906620.5 |
results = melt_results(model, X, y.flatten(), window_size)
px.line(results, x='Date', y='KG', color='Source')
🏋️ Exercise 3: Compare LSTM with FFNN using Train/Val/Test sets and 3 Month Window¶
### YOUR OPT WINDOW SIZE FROM EXERCISE 2 ###
window_size = 3
batch_size = 10
patience = 50
# training on single order history
data = orders.loc[[0], time_cols].values
# describes the split train 0-.6/val .6-.8/test .8-1
train_test_val_ratios = [0.6, 0.8]
X_train, y_train, X_val, y_val, X_test, y_test = train_test_process(data,
train_test_val_ratios)
### YOUR EARLY STOPPING FORMULA ###
early_stopping = keras.callbacks.EarlyStopping(
patience=10,
min_delta=0.001,
restore_best_weights=True,
monitor='loss'
)
### YOUR MODEL FROM EX 6.3.3.2 ###
model = keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[window_size]),
layers.Dense(1)
])
### UNCOMMENT THE BELOW ###
# compile the model
model.compile(loss='mean_squared_error', optimizer='adam')
# fit the model
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
batch_size=batch_size,
epochs=10000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
print(pd.DataFrame(history.history).tail())
train size: 76
val size: 23
test size: 24
loss val_loss
796 274950.81250 705562.1875
797 278971.28125 726105.4375
798 283036.78125 696195.4375
799 284960.03125 723620.4375
800 279106.31250 691688.0000
We'll then record the mse performance of the model to later compare with the LSTM
results = []
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
results.append(['Dense', mse])
results
[['Dense', 444380.32838419516]]
We'll use the same parameters (window size, batch size, and early stopping to train the LSTM and compare the optimum FFNN architecture we previously used)
X_train = X_train.reshape(-1, 1, window_size)
y_train = y_train.reshape(-1, 1, 1)
X_val = X_val.reshape(-1, 1, window_size)
y_val = y_val.reshape(-1, 1, 1)
X_test = X_test.reshape(-1, 1, window_size)
y_test = y_test.reshape(-1, 1, 1)
model = keras.Sequential([
layers.LSTM(8, activation='relu', input_dim=window_size),
layers.Dense(1)
])
model.compile(loss='mean_squared_error', optimizer='adam')
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
batch_size=batch_size,
epochs=10000,
callbacks=[early_stopping],
verbose=0,
)
print(pd.DataFrame(history.history).tail())
WARNING:tensorflow:Layer lstm_1 will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
loss val_loss
836 273390.4375 673023.0625
837 271066.7500 694139.5625
838 275661.9375 705827.1875
839 274106.7500 680028.2500
840 270606.5000 691417.3750
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test.flatten(), y_pred.flatten())
results.append(['LSTM', mse])
Comparison of results:
pd.DataFrame(results, columns=['Model', 'Test MSE']).set_index('Model').astype(int)
| Test MSE | |
|---|---|
| Model | |
| Dense | 444380 |
| LSTM | 424835 |
As a last visualization in this exercise we'll look at the trian/val/test predictions along the actual
data = orders.loc[[0], time_cols].values
idx_split1 = int(data.shape[1]*train_test_val_ratios[0])
idx_split2 = int(data.shape[1]*train_test_val_ratios[1])
y_p_train = model.predict(X_train)
y_p_val = model.predict(X_val)
y_p_test = model.predict(X_test)
new = orders.loc[[0], time_cols].T.reset_index()
new.columns = ['Date', 'Real']
new['Train'] = np.nan
new.iloc[window_size:idx_split1,2] = y_p_train
new['Val'] = np.nan
new.iloc[idx_split1+window_size:idx_split2,3] = y_p_val
new['Test'] = np.nan
new.iloc[idx_split2+window_size:,4] = y_p_test
new = new.melt(id_vars='Date', var_name='Source', value_name='KG')
px.line(new, x='Date', y='KG', color='Source')
6.5 Model Extensibility¶
from ipywidgets import interact
🏋️ Exercise 4: Apply Model to Other Orders¶
Take the last LSTM model and apply it to other orders in the dataset. What do you notice?
def apply_model(dataset=orders.index, window_size=3):
window_size = window_size
data = pd.DataFrame(orders.loc[dataset, time_cols])
data = data.reset_index()
data.columns = ['Date', 'KG']
X, y, labels = process_data(orders.loc[[dataset],
time_cols].values,
window=window_size,
time_cols=132)
y_pred = model.predict(X.reshape(-1, 1, window_size)).flatten()
results = pd.DataFrame(y_pred, y)
results = results.reset_index()
results.index = data['Date'][window_size:]
results = results.reset_index()
results.columns=['Date', 'real', 'predicted']
results = results.melt(id_vars='Date', var_name='Source', value_name='KG')
fig = px.line(results, x='Date', y='KG', color='Source')
return fig
interact(apply_model)
interactive(children=(Dropdown(description='dataset', options=(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 1…
<function __main__.apply_model>
🏋️ Exercise-Discussion 5.1: How Would You Create a General Forecast Model?¶
After exploring how your model does on other order histories, what do you think is a good strategy for developing company wide order forecasts?
Some possible questions:
- should you create a single model for the whole company?
- could you embed meta data about the order in this all-inclusive model?
- should you make models specific to certain customers, products, etc.
- what kind of analysis could you do before hand to determine how your models should be grouped?
melted = orders.melt(id_vars=['base_cake', 'truffle_type', 'primary_flavor', 'secondary_flavor',
'color_group', 'customer'], var_name='month', value_name='kg')
def my_eda(color=cat_cols):
fig = px.line(melted, x='month', y='kg', color=color)
return fig
interact(my_eda)
interactive(children=(Dropdown(description='color', options=('base_cake', 'truffle_type', 'primary_flavor', 's…
<function __main__.my_eda>
🏋️ Exercise 5.2: EDA¶
In our quest to create a model that works well for all orders to truffltopia. I tell you that there are some orders with patterned behavior, according to their meta data. Your first task, is to find out which categorical variable best separates the data. You can use any statistical or visual method you like
# recall the categorical variables:
['base_cake', 'truffle_type', 'primary_flavor', 'secondary_flavor', 'color_group', 'customer']
From C1 S6, it may be useful to think of this diagram:
🏋️ Exercise 5.3: Decide on Model¶
Will you model the whole dataset together? Will you create a number of submodels? Choose based on the groupings you determined statistically significant in the data.
As a base comparison I have provided a formula that trains a model on the entire order history:
data = orders
data = data[time_cols].values
batch_size = 256
window_size = 12
print("batch size: {}".format(batch_size))
print("window size: {}".format(window_size), end='\n\n')
# describes the split train 0-.6/val .6-.8/test .8-1
train_test_val_ratios = [0.8, 0.9]
X_train, y_train, X_val, y_val, X_test, y_test = train_test_process(data,
train_test_val_ratios,
window_size)
early_stopping = keras.callbacks.EarlyStopping(
patience=50,
min_delta=0.001,
restore_best_weights=True,
monitor='loss'
)
model = keras.Sequential([
layers.Dense(8, input_shape=[window_size]),
layers.Dense(16),
layers.Dense(32),
layers.Dense(16),
layers.Dense(1)
])
model.compile(loss='mean_squared_error', optimizer='adam')
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
batch_size=batch_size,
epochs=10000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
print(pd.DataFrame(history.history).tail())
data = orders
data = data[time_cols].values
batch_size = 256
window_size = 12
print("batch size: {}".format(batch_size))
print("window size: {}".format(window_size), end='\n\n')
# describes the split train 0-.6/val .6-.8/test .8-1
train_test_val_ratios = [0.8, 0.9]
X_train, y_train, X_val, y_val, X_test, y_test = train_test_process(data,
train_test_val_ratios,
window_size)
early_stopping = keras.callbacks.EarlyStopping(
patience=50,
min_delta=0.001,
restore_best_weights=True,
monitor='loss'
)
model = keras.Sequential([
layers.Dense(8, input_shape=[window_size]),
layers.Dense(16),
layers.Dense(32),
layers.Dense(16),
layers.Dense(1)
])
model.compile(loss='mean_squared_error', optimizer='adam')
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
batch_size=batch_size,
epochs=10000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
)
print(pd.DataFrame(history.history).tail())
batch size: 256
window size: 12
train size: 9300
val size: 100
test size: 200
loss val_loss
178 273904.93750 533661.50000
179 288718.50000 519464.28125
180 295474.71875 513898.46875
181 299524.78125 664799.06250
182 283324.56250 509953.53125
And a history of the loss with the following settings:
batch size: 256
window size: 12
train size: 9300
val size: 100
test size: 200
loss val_loss
326 279111.15625 953265.0625
327 322529.15625 580780.2500
328 285901.56250 476007.4375
329 302237.68750 496192.8125
330 281779.40625 480916.6250
interact(apply_model)