![]()
Data Science Foundations
X2: Airbnb¶
Instructor: Wesley Beckner
Contact: wesleybeckner@gmail.com
Today we are going to take our newfound knowledge from the course, and practice how we can leverage data to build predictive models. We'll start with a feature engineering problem on some dummy data. This will get us thinking creatively about problem solving. We will then pivot over to an Airbnb dataset. After performing some general, exploratory data analysis, we will solve the following business case: Airbnb is interested in using historical list prices from their airbnb hosts, to make pricing suggestions to new hosts. How can we use this existing datset to assist with this price listing suggestion?
Prepare Environment and Import Data¶
# basic packages
import pandas as pd
import numpy as np
import random
import copy
# visualization packages
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns; sns.set()
import graphviz
# stats packages
import scipy.stats as stats
from scipy.spatial.distance import cdist
import statsmodels.api as sm
from statsmodels.formula.api import ols
from statsmodels.stats.outliers_influence import variance_inflation_factor
# sklearn preprocessing
from sklearn.preprocessing import OneHotEncoder, StandardScaler, PolynomialFeatures
from sklearn.decomposition import PCA
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
# sklearn modeling
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.mixture import GaussianMixture
# sklearn evaluation
from sklearn.metrics import mean_squared_error, r2_score, accuracy_score
from sklearn.model_selection import GridSearchCV, cross_val_score
Warm Up¶
Add aditional feature(s) to X to predict y with a linear classifier (e.g. logistic regression)
from sklearn.datasets import make_circles
X, y = make_circles(random_state=42, noise=.01)
relabel = dict(zip([0,1,2,3],[0,1,0,1]))
y = np.vectorize(relabel.get)(y)
plt.scatter(X[:,0], X[:,1], c=y, cmap='viridis')
<matplotlib.collections.PathCollection at 0x7f20ec66d280>
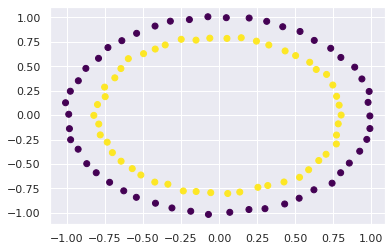
and now predict
# consider using
# LogisticRegression()
# r2_score
Exploratory Data Analysis¶
which columns are numerical, string; which contain nans/nulls; what is the correlation between features
airbnb = pd.read_csv("https://raw.githubusercontent.com/wesleybeckner/datasets/main/datasets/airbnb/AB_NYC_2019.csv")
# recall these attributes
# shape dtypes
# and these methods
# head() tail() isnull() sum() nunique() copy() select_dtypes() describe() drop()
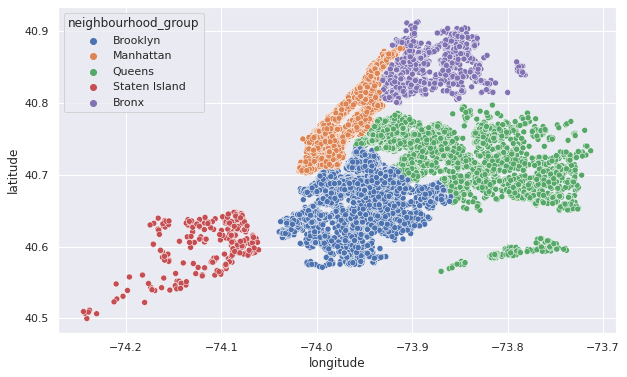
what visualizations would be useful to make?
plt.figure(figsize=(10,6))
sns.scatterplot(x=airbnb.longitude,y=airbnb.latitude,hue=airbnb.neighbourhood_group)
<AxesSubplot:xlabel='longitude', ylabel='latitude'>
Feature Engineering¶
Say we want to predict price, using an ML model. How would you build your features?
Based on the number of null values, what would you do with the last_review and reviews_per_month column?
X = airbnb.copy()
How will we deal with the categorical features?
# Recall
# OneHotEncoder()
X_cat = X.select_dtypes(include='object')
display(X_cat.head())
print(X_cat.nunique())
| name | host_name | neighbourhood_group | neighbourhood | room_type | last_review | |
|---|---|---|---|---|---|---|
| 0 | Clean & quiet apt home by the park | John | Brooklyn | Kensington | Private room | 2018-10-19 |
| 1 | Skylit Midtown Castle | Jennifer | Manhattan | Midtown | Entire home/apt | 2019-05-21 |
| 2 | THE VILLAGE OF HARLEM....NEW YORK ! | Elisabeth | Manhattan | Harlem | Private room | NaN |
| 3 | Cozy Entire Floor of Brownstone | LisaRoxanne | Brooklyn | Clinton Hill | Entire home/apt | 2019-07-05 |
| 4 | Entire Apt: Spacious Studio/Loft by central park | Laura | Manhattan | East Harlem | Entire home/apt | 2018-11-19 |
name 47905
host_name 11452
neighbourhood_group 5
neighbourhood 221
room_type 3
last_review 1764
dtype: int64
X_num = X.select_dtypes(exclude='object')
X_num.head()
| id | host_id | latitude | longitude | price | minimum_nights | number_of_reviews | reviews_per_month | calculated_host_listings_count | availability_365 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2539 | 2787 | 40.64749 | -73.97237 | 149 | 1 | 9 | 0.21 | 6 | 365 |
| 1 | 2595 | 2845 | 40.75362 | -73.98377 | 225 | 1 | 45 | 0.38 | 2 | 355 |
| 2 | 3647 | 4632 | 40.80902 | -73.94190 | 150 | 3 | 0 | NaN | 1 | 365 |
| 3 | 3831 | 4869 | 40.68514 | -73.95976 | 89 | 1 | 270 | 4.64 | 1 | 194 |
| 4 | 5022 | 7192 | 40.79851 | -73.94399 | 80 | 10 | 9 | 0.10 | 1 | 0 |
Feature Transformation¶
What features do you think will cause the most problems if untransformed?
Scale and Center all but the target variable, price
# Recall
# StandardScaler() df.pop()
Model Baseline¶
# Recall
# X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=42)
# LinearRegression()
# r2_score()
try a model that captures non-linear relationships
# Recall
# RandomForestRegressor()
both of these results from the LinearRegression and RandomForest models should indicate something to you (think back to Model Selection and Validation)
Additional Strategies¶
After this first pass, what are some additional strategies to consider for improving the model?